Adversarial Autoencoders
Published:
Short Notes on Adversarial Autoencoders
The Adversarial autoencoder (AAE) was proposed by Alireza Makhzani et al (2016). AAE is a generative model with two main objectives. First is to learn a compressed/ latent representation of data while ensuring that the learned latent representation follows a prior distribution we get to define.
For instance, with an autoencoder, we have en encoder block that encodes the input data into a fixed vector $z$ of potentially lower dimension that the input and retaining as much information as possible. If we want to retrieve the input data, we simply pass the latent vector ,$z$, to a decoder which attempts to create the data (reconstruct) into the original dimension.
One important point here is that the latent vector $z$ learned by the autoencoder is always fixed and the reconstructed data is pretty much the same each time the decoder reconstructs it. The $z$ is therefore useful if we want only to do dimensionality reduction.
For variational autoencoders, instead of encoding the input data into a fixed vector ,$z$, the encoder learns parameters $\mu$ and $\sigma$ of a distribution which can be reparameterized with samples from a simpler distribution say a standard gaussian (a gaussian distribution with mean 0 and standard deviation 1) to get the z vector ($z = \mu + \sigma \epsilon $, where $\epsilon \sim \mathcal{N}(0,1)$). This allows us to create new forms of the data by simply sampling from the standard gaussian and have the decoder reconstruct the data. Sometimes however, the prior distribution might be different from the learned distribution. Reconstructing the data from samples from the prior might therefore not be very useful.
The Adversarial autoencoder uses quite a bit different technique to impose the prior distribution on the latent code and besides, it allow some flexibility with the choice of prior distribution. By imposing a prior distribution on the latent code, we mean, we want the latent code to follow a prior distribution, say a gaussian distribution with mean 0 and standard deviation 1.
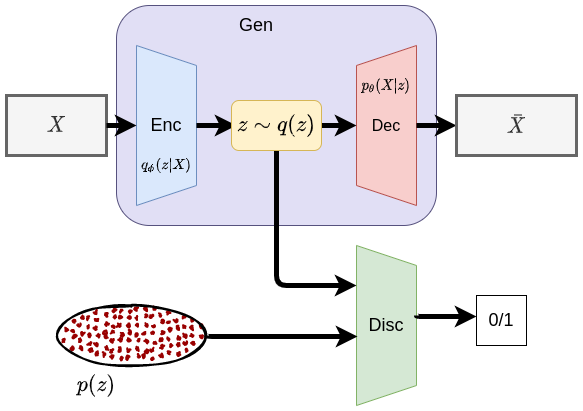
Fig 1. Adversarial Autoencoder architecture
The AAE is made up of a generator and a discriminator as in the generative adversarial network. The generator is made up of an encoder and a decoder as for an autoencoder and the discriminator is a simple neural network which produces a binary output (0/1).
Again, main objectives of the adversarial autoencoder is 1.) for the generator’s encoder to learn better representation for the input data and the decoder to be able to reconstruct the data as close as possible to the original input from the latent code. 2.) The discriminator should guide the generator’s encoder to produce a latent code that resembles samples from our prior distribution. Below, lets look at the two main training phases;
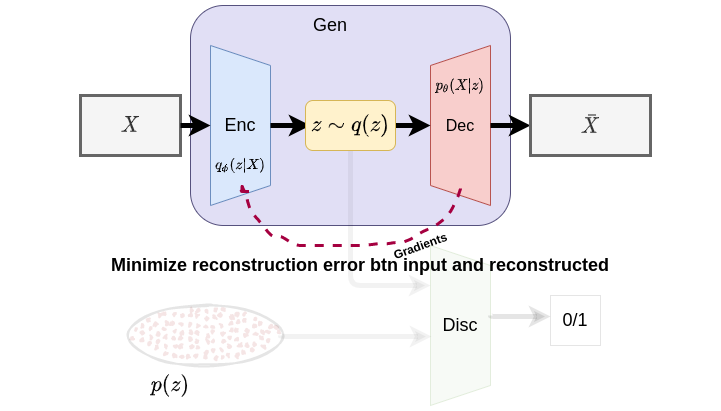
Fig 2. Reconstruction Phase: update generator (encoder + decoder)
Phase 1: The generator’s encoder encodes the input data into a latent representation whiles the decoder attempts to reconstruct the original data from the latent code. This represents the first training phase where the generator’s encoder and decoder are both optimized jointly to minimize reconstruction error in the generator.
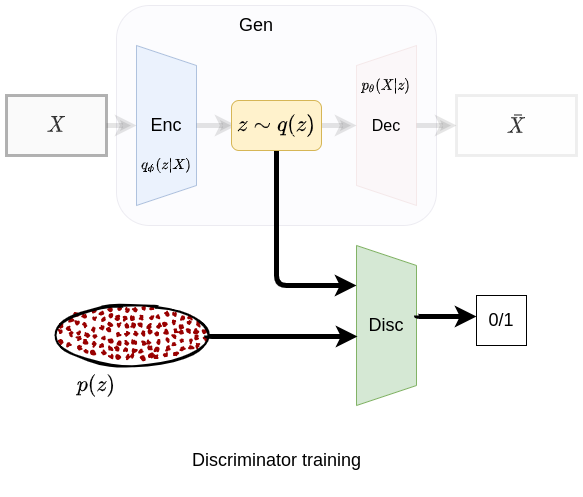
Fig 3. Regularization phase: discriminator training
Phase 2: i) The discriminator receives samples from the prior distribution and the latent code labeled as true/positive samples and false/ negative samples respectively. The samples are fed to the discriminator which is a neural network model with a binary output for this classification task. Only the discriminator’s parameters are updated at this point.
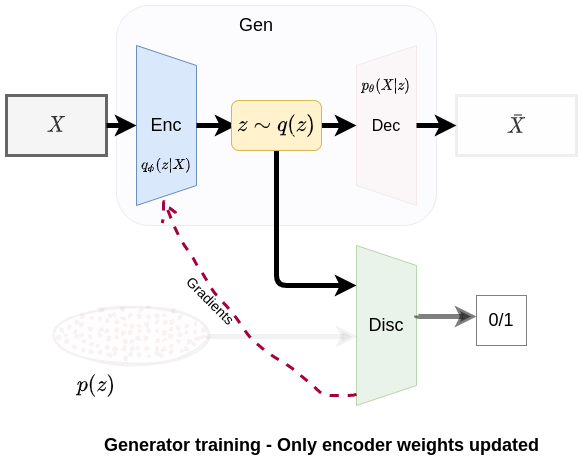
Fig 4. Regularization phase: encoder (generator) training
ii) In the second part of the regularization phase, the generator’s encoder trains to fool the discriminator to believe that the samples it has generated come from the prior distribution. If the latent code truly resembles samples from the prior distribution, then the generator yields a low loss and a high loss if otherwise. Gradients from the discriminator is propagated to the generator’s encoder to update its parameters (implementation detail: discriminator’s parameters should be frozen at this point).